AI-native, situation-aware next-generation (xG) networks move beyond reactive, pilot-centric operation toward proactive, context-driven operation. By unifying location awareness and environment awareness, the RAN (i) maintains a shared picture of movement, obstacles, and signal paths, (ii) anticipates changes, and (iii) makes timely decisions regarding beam and resource management. This post sketches how digital twin (DT)-aided localization and scene-informed channel modeling improves accuracy, reduces overhead, and establishes resilient links as conditions shift for xG networks design and operation. This research consists of two core components: 1) acquisition of situation awareness, and 2) design of proactive xG networks.
This research is part of an ongoing collaboration with NVIDIA. For more details, please follow: .
AI-Native Situational Awareness
Introduced in 5G NR Release 17, multi-transmission reception point (TRP) systems enable more accurate positioning in xG networks, as each TRP can serve as a reference node. As depicted below, the TRPs are distributed throughout a designated area and are connected to the central unit.
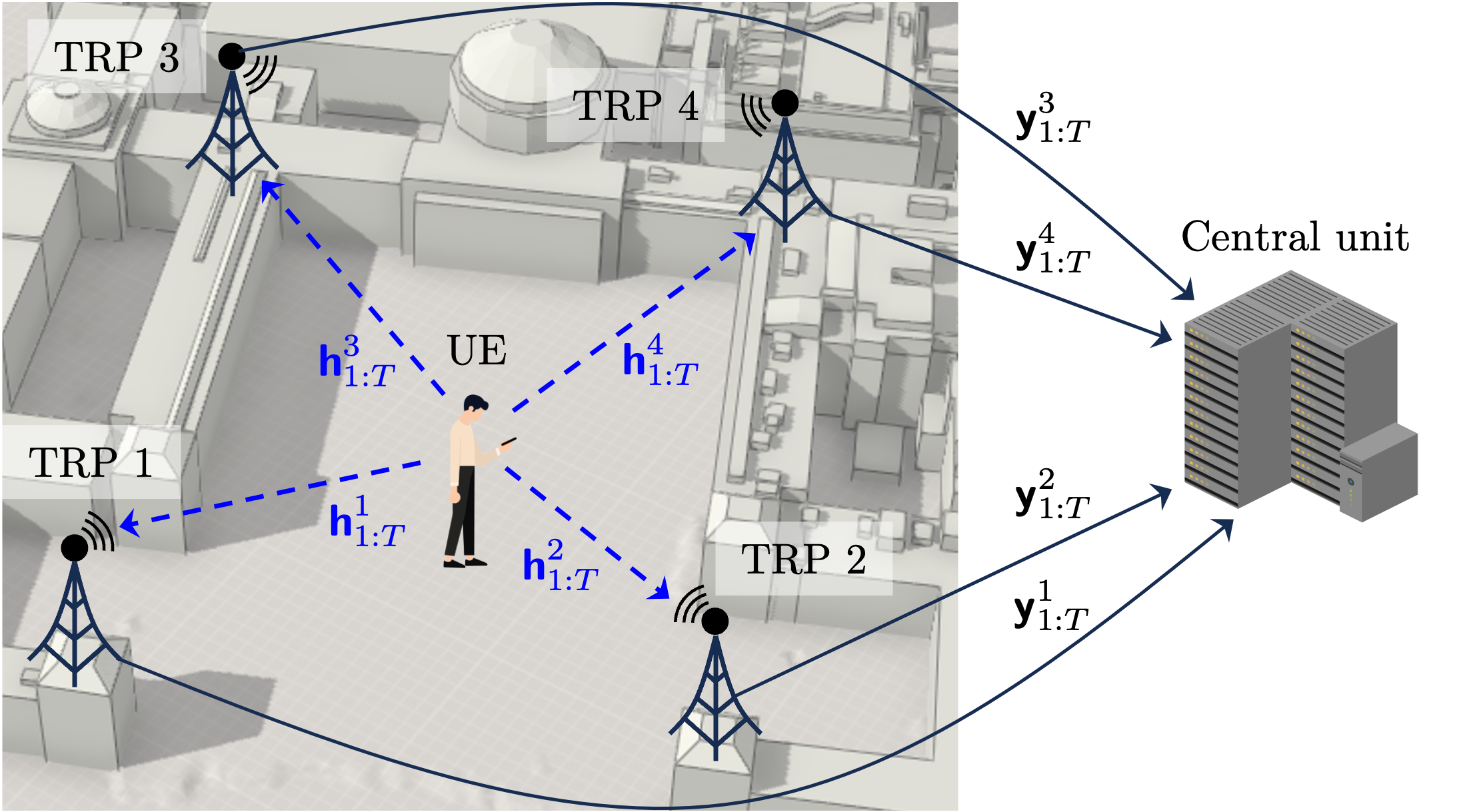
Fig. 1-1. Illustration of multi-TRP systems.
The main challenge of positioning is achieving high accuracy and reliability in environments with significant multipath and blockages (e.g., street canyons, indoors). A promising strategy for accurate positioning is to address this challenge is to use an AI-based approach. In WINS Lab, we emulate the multi-TRP systems and generate training dataset on 40,635 square meters of MIT’s campus in Cambridge, Massachusetts, using NVIDIA Sionna software and A100 GPUs (see figure below).
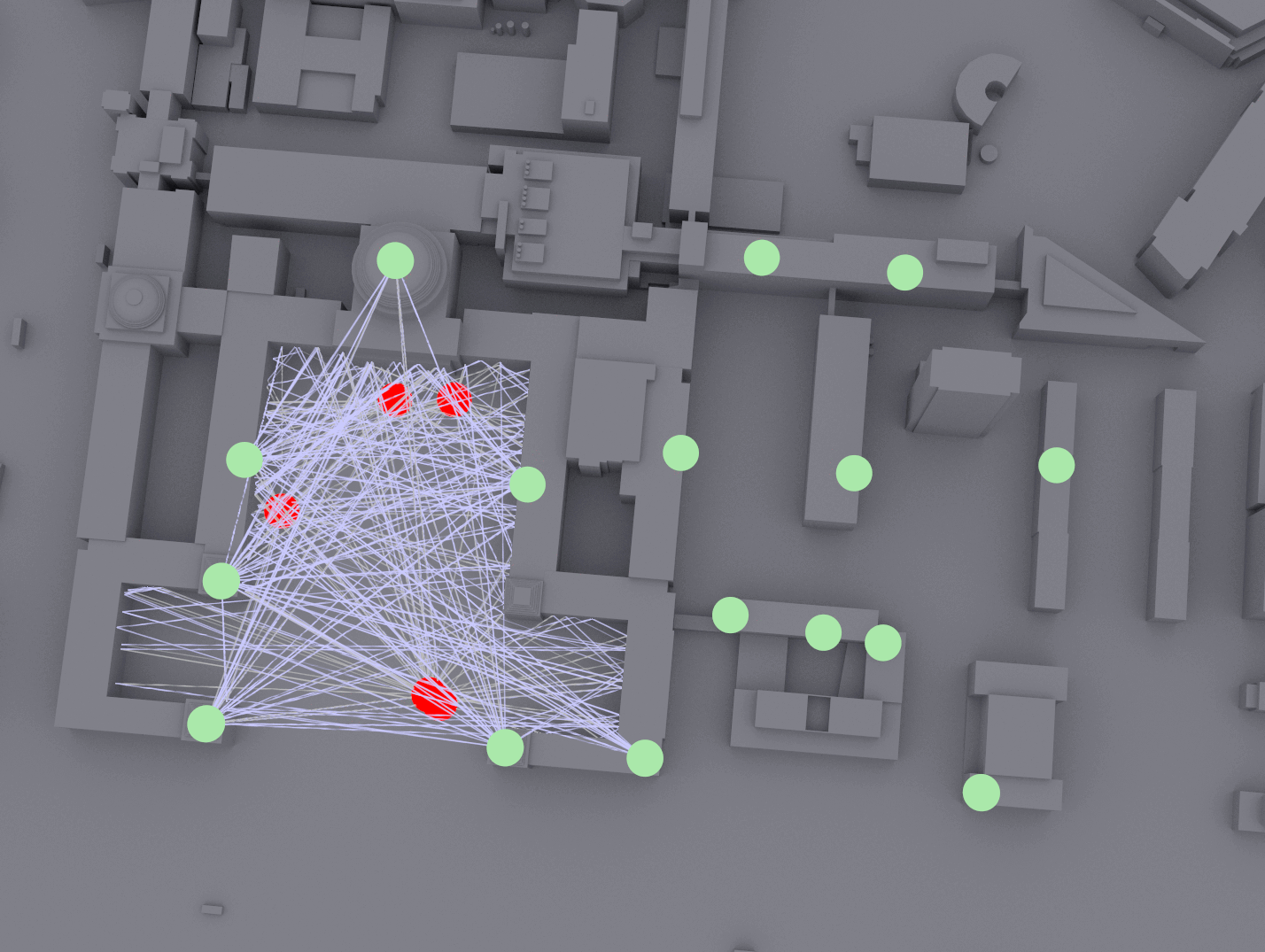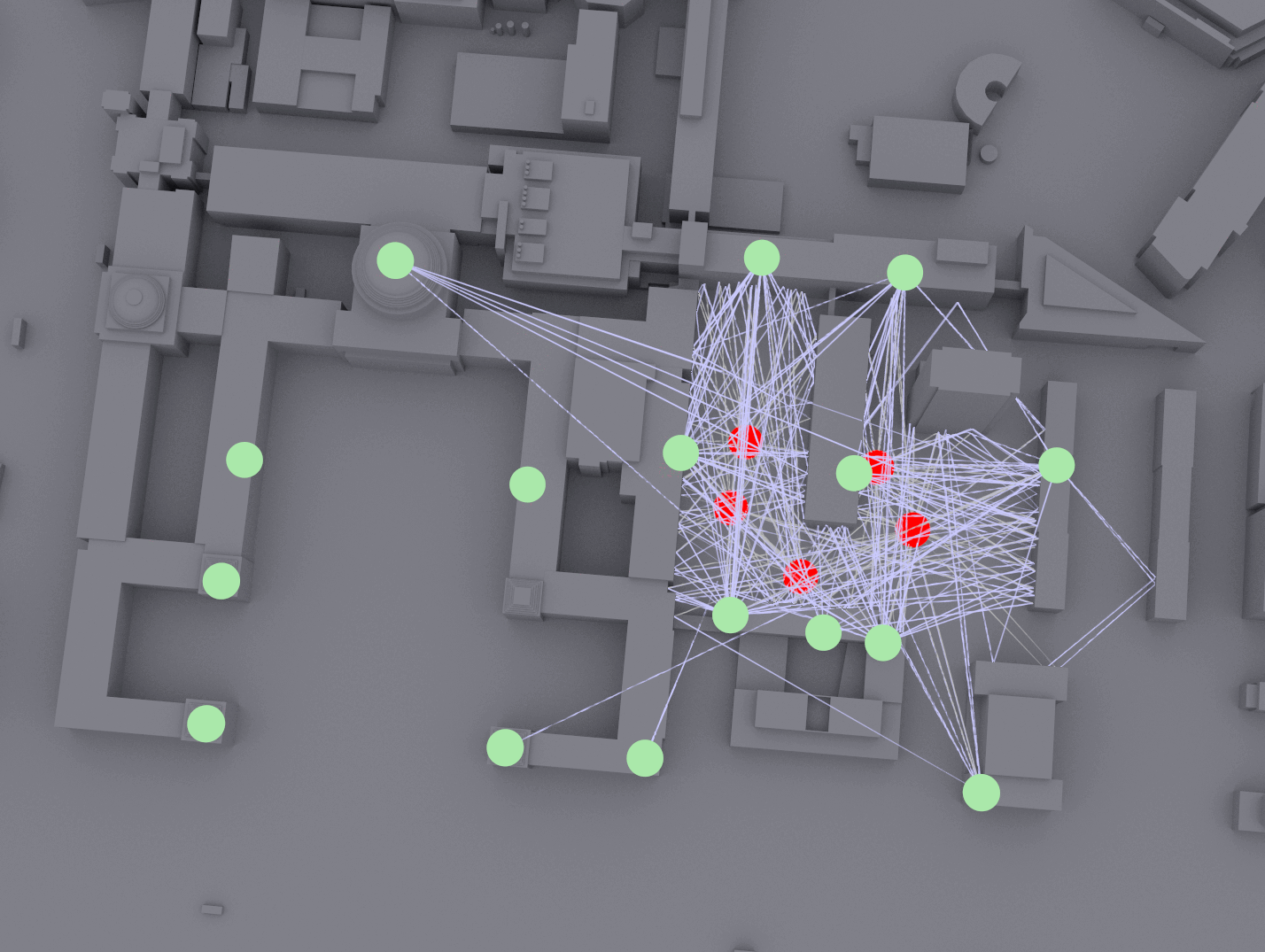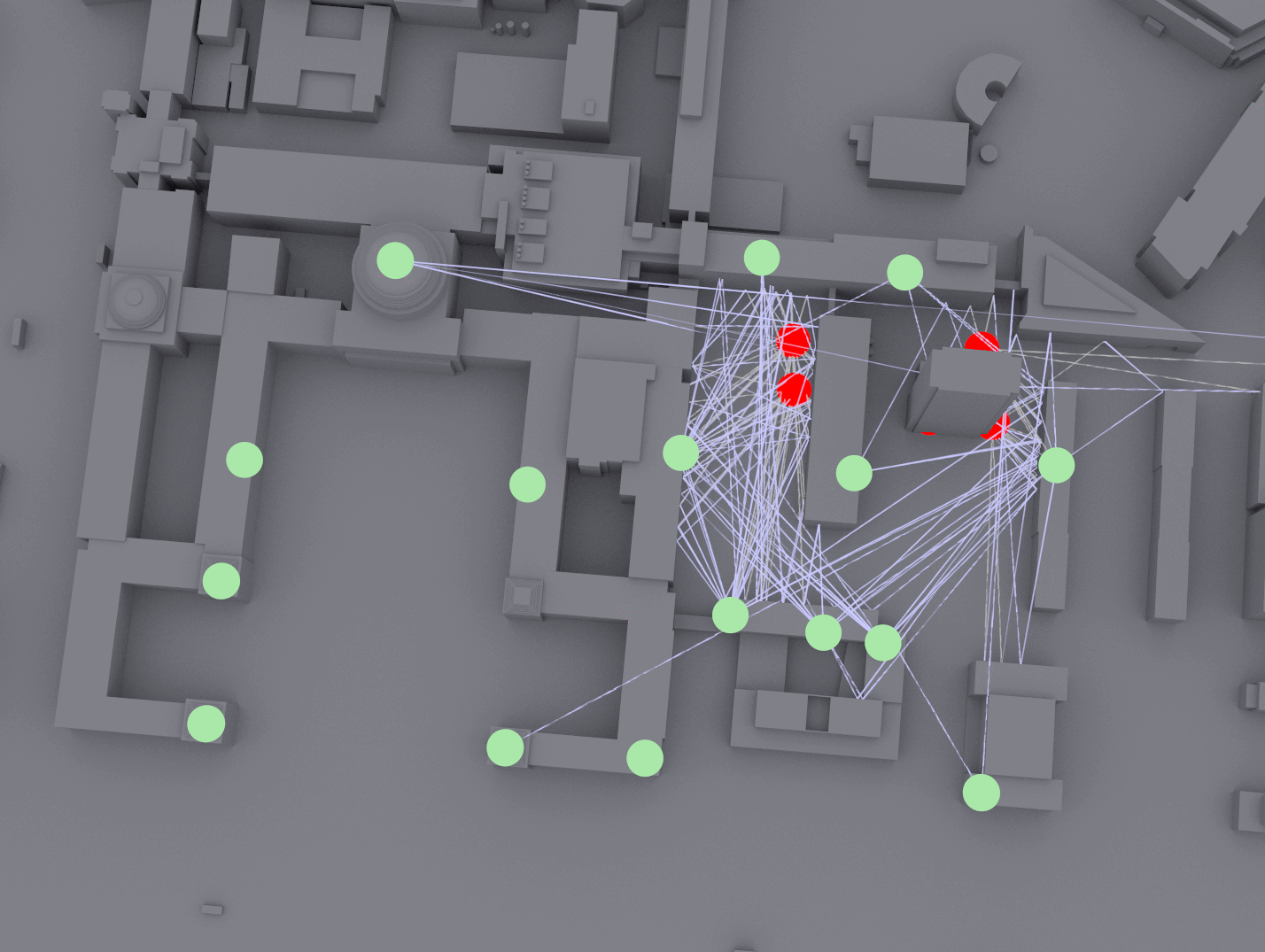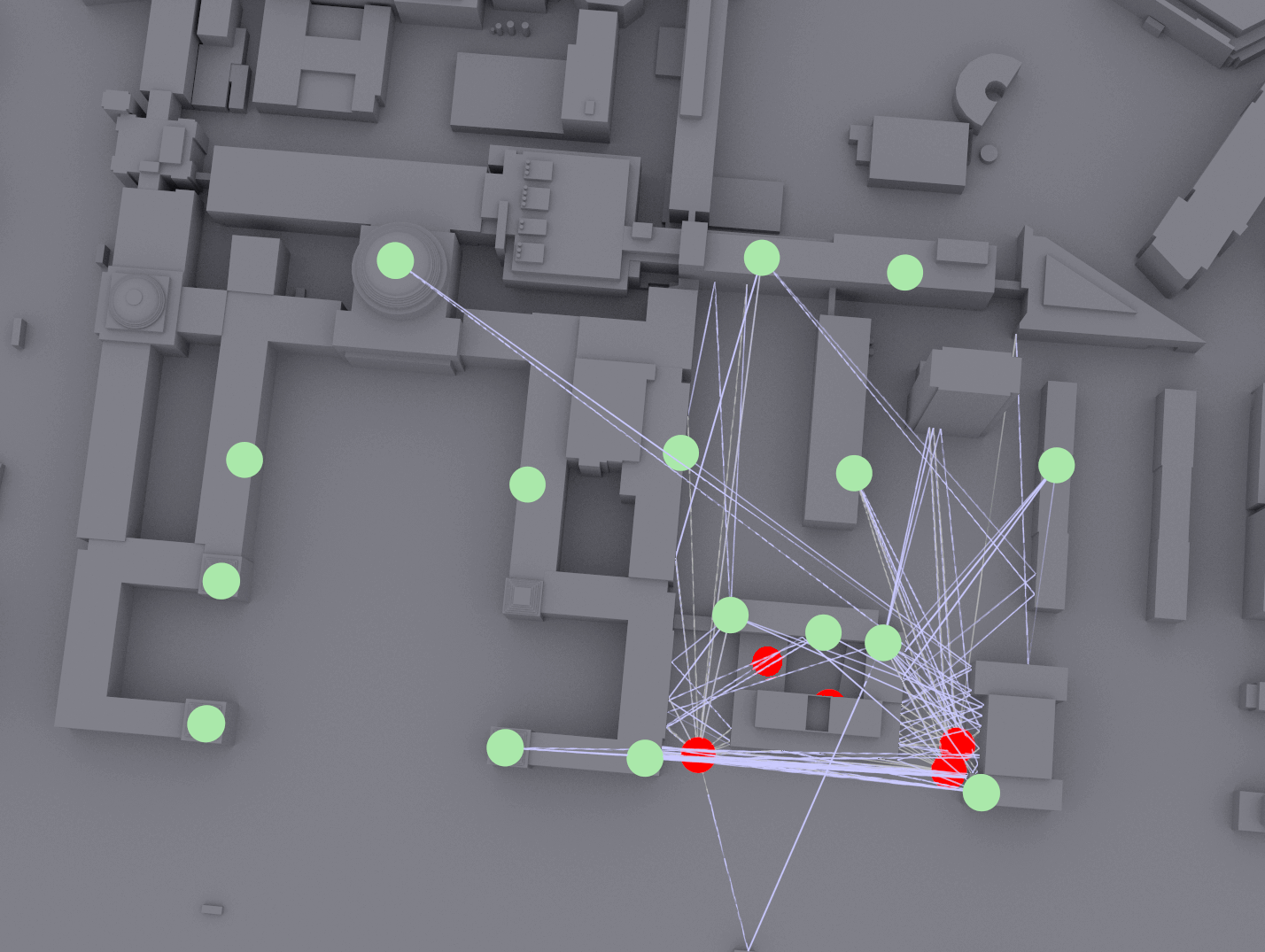
Fig. 1-2. Channel emulation at the MIT campus using NVIDIA Sionna.
Unlike the previous AI-based methods for positioning, the one proposed by WINS Lab at MIT is designed to integrate insights from anchor node selection leveraging geometrical relationships. A key enabler of this new positioning method is the transformer encoder, which can effectively extract a token (i.e., latent representation of channel features) from each selected TRP. Based on these tokens, the user position is inferred by multi-head attention pooling (MHAP), enabling a more lightweight model design compared to fully connected (FC) layers. This design offers enhanced localization accuracy, as well as more compact design, compared to previous transformer-based methods. Both training and validation were carried out by Supermicro MGX systems equipped with NVIDIA GH200.
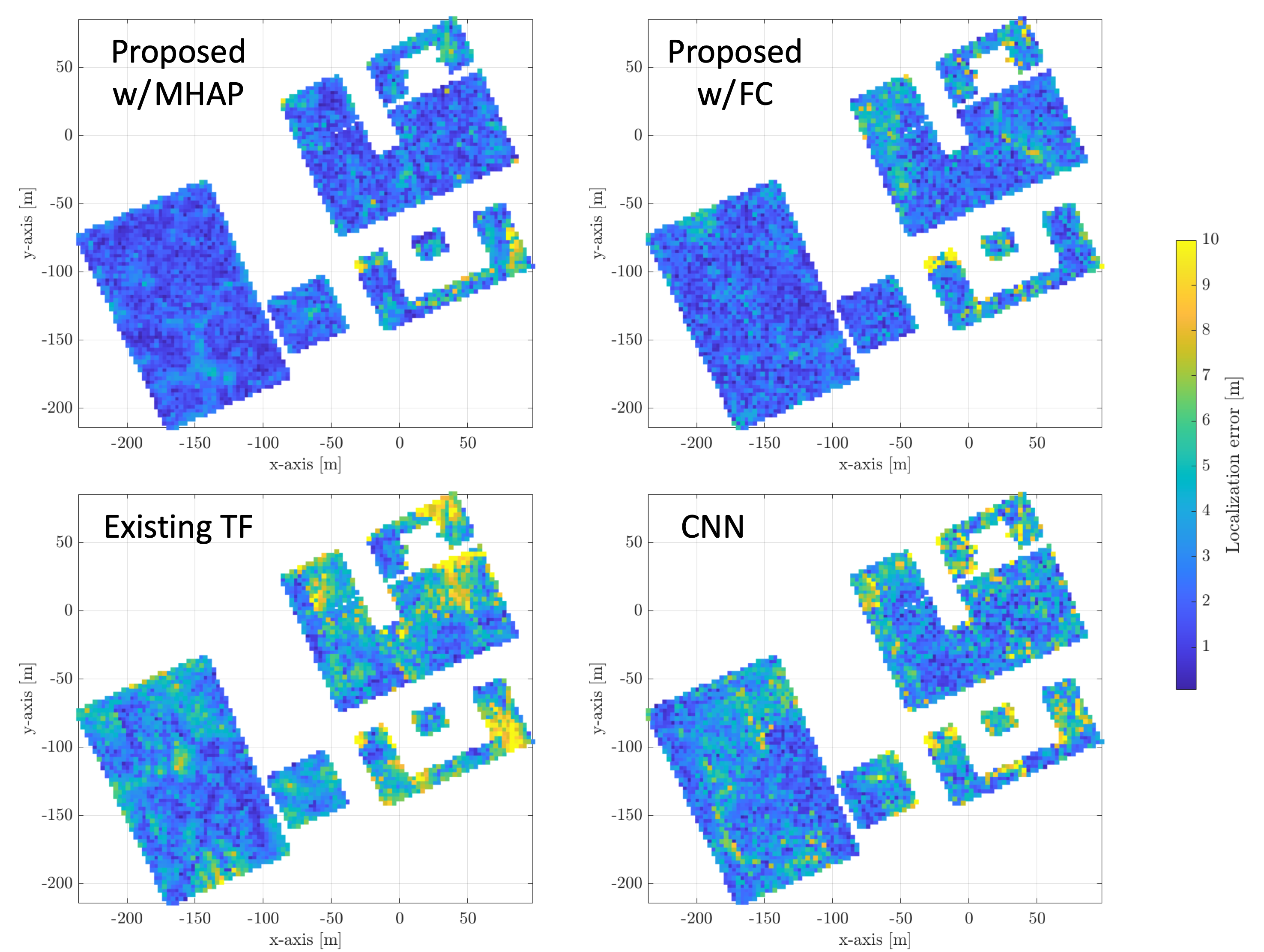
Fig. 1-3. Localization accuracy heatmaps obtained by different AI models.
Another benefit of the proposed model is that it allows easy fine-tuning. This fine-tuning enables adaptation of the model to new environments with significantly lower training overhead than training a new model from scratch. We performed tests in other parts of MIT’s campus, and the results showed that the fine-tuning proposed model reduces training overhead by 46% without losing localization accuracy.
Situation-Aware Proactive xG Networks
xG wireless networks are moving into frequency bands where beams are sharp, links are sparse, and obstacles can change the scene in an instant. Pilot-based wireless system architectures that react after channel drift are not enough for high mobility or cluttered layouts. Environmental awareness turns the surrounding world into useful signal context, so that networks can predict what comes next.
A unifying idea here is the channel knowledge map (CKM): a learned mapping from user position to wireless channel that compresses the spatial structure of propagation. End-to-end CKM learning can cut pilot transmissions, but this approach tends to be data-hungry because the output scales with antennas and time-frequency resources. Moreover, digital-twin approaches require ongoing calibration to provide realistic predictions. That hinders real-time decisions. In earlier works, CKMs relied on geometric channel parameters (GCPs) such as angles, delays, and path gains. Generalization across positions and fast adaptation suffers under abrupt transitions.
Fig. 2-1. Illustration of VCP-based CKM construction.
The new approach proposed by WINS Lab at MIT reframes CKMs around visual channel parameters (VCPs). Instead of describing the channel only by angles and delays, the VCP-based approach works with reflection points and scatterer indices that depict the scene geometry directly. The proposed CKMs are a composition of three submaps: a reflection map from position to VCPs, a conversion map from VCPs to GCPs, and a geometric map from GCPs to the channel. VCPs inject contextual knowledge about objects and boundaries, which is the missing piece for handling sudden blockages and multipath changes.
Fig. 2-2. Overview of VCP-based CKM learning.
Building on this three-map construction, WINS Lab at MIT has proposed a method that learns the reflection map with a large multimodal model [1]. It fuses synchronized RGB-D frames and pilot snapshots, then performs two core tasks: scatterer index classification to select which objects are active reflectors, and reflection point regression to estimate the 3D interaction point on each. The resulting visual channel parameters feed the conversion and geometric maps, enabling proactive channel prediction and beam management as scenes evolve.
Fig. 2-3. Block diagram of CKM-based beam management.
Situational awareness naturally extends to beam management [2]. By tracking VCPs over time with a prediction-and-update cadence, the system forecasts trajectories, identifies which objects are currently reflecting, predicts where reflections will land next, and steers training and downlink beams before the scene changes. This directly addresses piecewise continuity and avoids focusing only on the line-of-sight (LOS) path by also accounting for non-line-of-sight (NLOS) components.
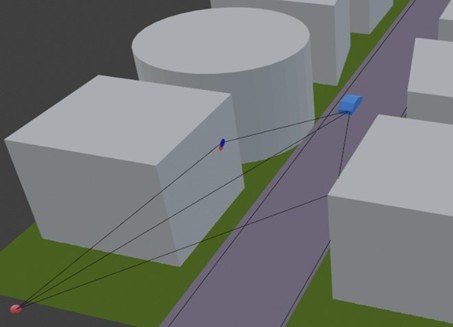
Fig. 2-4. Visual comparison of predicted (red dot) and ground truth reflection point (blue dot).
Numerical results show strong reflection tracking and channel prediction: more than 92% correct scatterer identification while keeping reflection point error below 45cm and substantial channel prediction gains over GCP-based baselines.
The takeaway is: treat the environment as data by building a CKM with VCPs so that networks can act proactively: estimate channels along the trajectories of users, optimally set beams along said trajectories, and keep sessions resilient as scenes evolve. The same formulation pairs well with DT pipelines while keeping real-world calibration in the loop, charting a practical course to AI-native RAN research and development of proactive xG wireless networks.
References
- S. Kim, S. Saha, S. Jeong, B. Shim, and M. Z. Win, “Large multimodal model-based environment-aware beam management,” to appear in IEEE Journal on Selected Areas in Communications, 2025.
- S. Kim, S. Jeong, J. Wu, B. Shim, and M. Z. Win, “Large multimodal model-based environment-aware channel estimation,” to appear in IEEE Journal on Selected Areas in Communications, 2025.